
Evaluating a machine learning model is one of the most critical steps in data science. Model evaluation ensures that the model built fits the data and generalises well to new, unseen data. Simply put, it’s like taking a test drive before committing to a car purchase—you want to be sure it works in the real world, not just in the showroom.
Model evaluation answers important questions like:
- How well does the model perform on seen and underseen data?
- Does it overfit or underfit the data?
Without a proper model evaluation, you could build a model that looks great on paper but fails miserably when applied to new data. That’s why we use techniques like train-test split and cross-validation to ensure the reliability of our models.
Let’s break it all down and explore how these techniques help us build models that perform well on real-world data.
Why Model Evaluation is Important
Before we dive into the methods, let’s discuss why model evaluation matters. When we build a machine learning model, we aim for it to perform well on future data—not just the data we used for training. Without proper evaluation, we risk building a model that overfits (Captures patterns in training data too well and does not generalise) or underfits (fails to capture important patterns).
To avoid these pitfalls, we must assess the model’s performance on data it hasn’t seen before. This ensures the model is both accurate and generalised.
The famous “Netflix Prize” competition, where data scientists competed to improve movie recommendations, showed the critical importance of evaluation. Many early models performed well on the training data but failed on new movie ratings, emphasizing the need for proper evaluation techniques like cross-validation.
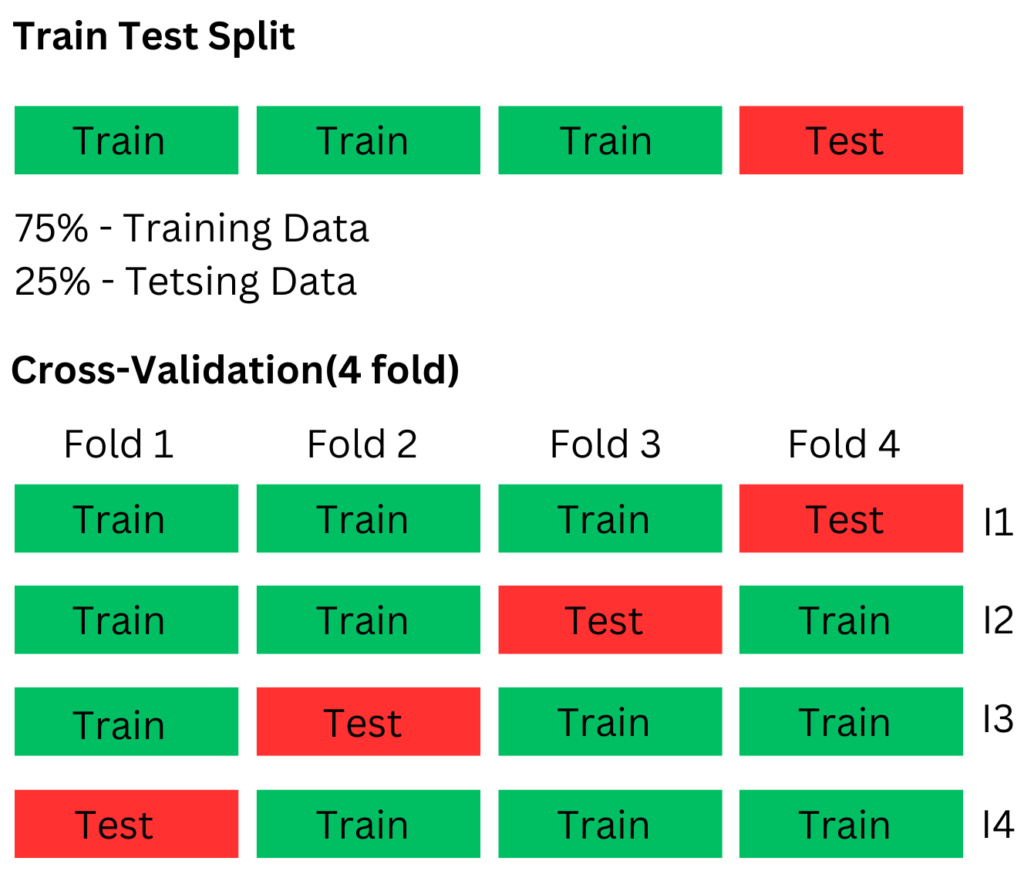
Train-Test Split: The Classic Approach
The train-test split method is the simplest and most commonly used model evaluation technique. The idea is to split the available data into two sets:
- Training Set(Seen Data): Used to train the model.
- Test Set(Unseen Data): Used to evaluate how well the model generalizes to unseen data.
Typically, we split the data into 70–80% for training and 20–30% for testing. Once we train the model on the training set, we evaluate its performance using the test set.
Refer here for the train test split function from the sci-kit learn package.
We can additionally use a validation set to tune the model hyperparameters. We use the training data to train the model, the validation set to determine which parameter settings work best, and the test data to assess the model’s performance on completely unseen data. Since the validation data helps select the best model, it’s also considered “seen” data by the model.
Advantages of Train-Test Split:
- Simplicity: It’s easy to implement and quick to run.
- Efficiency: Suitable when you have a lot of data, making the evaluation process faster.
Disadvantages of Train-Test Split:
- Limited Insight: The performance can vary depending on how the data is split. If you’re unlucky with the split (where all similar data points might end up in the test set), you could get misleading results. To avoid this, we can use stratification based on certain external factors to ensure a more balanced and representative split.
- Data Size Dependency: If you don’t have enough data, splitting it can lead to high variance in model performance and data would be insufficient to train.
Cross-Validation: A More Robust Evaluation
Cross-validation is a more reliable and preferred technique for model evaluation, especially when dealing with limited data. The most popular version is k-fold cross-validation, where we divide the data into k subsets or “folds.” We train the model on k-1 folds and test it on the remaining fold, rotating through until each fold has been used for testing. This process repeats k times, with each fold serving as the test set once. With this, we can overcome the disadvantage of a random split in the train-test split approach.
Refer here on how to use cross-validation for model evaluation using sci-kit learn.
For example, in 5-fold cross-validation, the data is split into five equal parts. The model trains on four of them and tests on the fifth, rotating until every part has been tested. The final performance is the average of all five tests.
Advantages of Cross-Validation:
- More Reliable: By testing on multiple folds, you get a more accurate estimate of the model’s performance.
- Better Use of Data: Every observation gets a chance to be in both the training and test sets, providing a more comprehensive evaluation.
Disadvantages of Cross-Validation:
- Time-Consuming: It requires training and testing the model multiple times, which can be computationally expensive.
- Complexity: Cross-validation can be harder to implement compared to the train-test split, especially for large datasets.
Train-Test Split vs Cross-Validation: Which One to Use?
Now that we’ve looked at both methods, the big question is: Which one should you use?
When to Use Train-Test Split:
- Large Datasets: When you have an abundance of data, splitting it into training and test sets works well. You can afford to have enough data in both sets to ensure the model is tested thoroughly.
- Quick Testing: If you’re just experimenting with models or parameters and need quick feedback, the train-test split method is faster and simpler.
When to Use Cross-Validation:
- Limited Data: When your dataset is small, cross-validation ensures that you make the most out of your available data.
- Model Selection: If you’re trying to compare multiple models, cross-validation provides a more robust estimate of how each model performs on average.
- Avoiding Variability: In cases where the dataset is unbalanced or you suspect that a simple train-test split might not give a good estimate, cross-validation helps by averaging results across multiple tests.
Other Model Evaluation Techniques
While train-test split and cross-validation are the most common methods, there are a few other evaluation techniques worth mentioning:
1. Leave-One-Out Cross-Validation (LOO-CV)
This is a special case of cross-validation where k equals the number of data points. Each data point is used once as a test set while the rest of the data serves as the training set. It’s a highly exhaustive technique but can be computationally very expensive.
2. Stratified Cross-Validation
This is a variant of k-fold cross-validation used when the dataset is imbalanced. It ensures that each fold has approximately the same proportion of each class label as the original dataset.
3. Time Series Cross-Validation
For time series data, regular cross-validation doesn’t work well due to temporal dependencies. In this method, we keep the temporal order intact by training the model on past data and testing on future data.
Advantages and Disadvantages Recap
| Technique | Advantages | Disadvantages |
| Train-Test Split | Simple, quick, and efficient on large datasets | Can give misleading results with small data |
| Cross-Validation | More reliable, makes better use of limited data | More computationally expensive, time-consuming |
| Leave-One-Out (LOO) | Uses all data points for training, very thorough | Extremely time-consuming for large datasets |
| Stratified CV | Ideal for imbalanced datasets, maintains class distribution | Adds complexity to the implementation |
| Time Series CV | Keeps time dependency intact, ideal for sequential data | Can be complex and tricky to implement |
Conclusion: Simplifying Model Evaluation
In the world of machine learning, model evaluation is as important as model building itself. Techniques like train-test split and cross-validation ensure that our models don’t just memorize the training data but also perform well on new data. While train-test split is simple and works well with large datasets, cross-validation provides more reliable results, especially when data is limited.
When deciding which technique to use, consider the size of your dataset, the complexity of your model, and the computational resources available. By understanding the pros and cons of each approach, we are better equipped to evaluate our models accurately and build systems that are reliable in the real world.
And remember, just like in life, balance is key—don’t always trust your first split! Happy modelling!