
Researchers consider Natural Language Processing (NLP) an important area within artificial intelligence (AI) that aims to help computers grasp, interpret, and produce human language in a way that makes sense. We will break down what NLP is all about, where people use it, and why it matters. In this blog, we will explore NLP and focus on the major steps that involve text processing. So if you are new to NLP or have your fair share of knowledge in this domain, we have curated this blog just for you!
What is NLP?
NLP brings together computational linguistics, which looks at language through the lens of computer science, with machine learning and deep learning methods. This mix enables computers to handle and make sense of huge volumes of natural language data, making it easier for people to communicate with machines, whether by talking or writing.
What makes NLP so special? Well, Machines are educated to grasp the meanings and contexts inherent in human language. Computers possess the capability to generate coherent text or speech that emulates human communication. Hence , Natural Language Processing facilitates various tasks, including the translation of text, summarization of information, and extraction of pertinent data from extensive datasets.
Applications of NLP
- Virtual Assistants:
- Technologies like Siri, Alexa, and Google Assistant use NLP to understand user commands and provide relevant responses. They continuously improve their contextual understanding and personalization capabilities.
- Text Translation:
- Services such as Google Translate utilize NLP algorithms to convert text between languages while preserving meaning. This helps break down language barriers and facilitates global communication.
- Sentiment Analysis:
- Businesses analyze customer feedback using NLP to gauge public sentiment about their products or services. This insight helps organizations tailor their strategies based on real-time consumer opinions.
- Chatbots:
- Automated systems powered by NLP handle customer inquiries in real-time, providing immediate assistance and enhancing user experience. Chatbots learn from interactions, improving their effectiveness over time.
Stages of Text Processing in NLP
When working on NLP related projects, one should pay focus on the following stages and make sure that the techniques they you matches with the project outcomes. Here are some basic steps that you can follow while make an NLP project-
Text-Preprocessing
Splitting text into smaller pieces called tokens (words or phrases). E.g. The sentence "The creativity of mind." becomes ["The", "creativity", "of", "mind", "."]. This facilitates the division of text into manageable segments for the purpose of analysis.
- Lowercasing: Converting all text to lowercase ensures uniformity. For example,
"Apple"and"apple"are treated the same. - Stop Word Removal: Removing common words like
"is," "the," and "and"since they don’t add much meaning to the analysis. - Stemming: Reduces words to their root form without considering meaning.
Example:"running"→"run". - Lemmatization: Reduces words to their base or dictionary form, considering context.
Example:"better"→"good". - Text Cleaning: Getting rid of extra stuff like punctuation, HTML tags, or special characters to make a tidy dataset for analysis.
Feature Extraction
After cleaning the text, it needs to be changed into a format that machines can understand (numbers). Key methods include:
- Bag of Words (BoW): This method counts how many times each word appears in a document, without considering the order of the words. For example, in the reviews “I love coffee” and “I hate coffee,” BoW would count the words “I,” “love,” “hate,” and “coffee.”
- Term Frequency-Inverse Document Frequency (TF-IDF): This technique measures how often a word appears in a document and compares it to how uncommon that word is in all documents. Words like “love” and “great,” which are rare and significant, will be given more weight than common words like “the.”
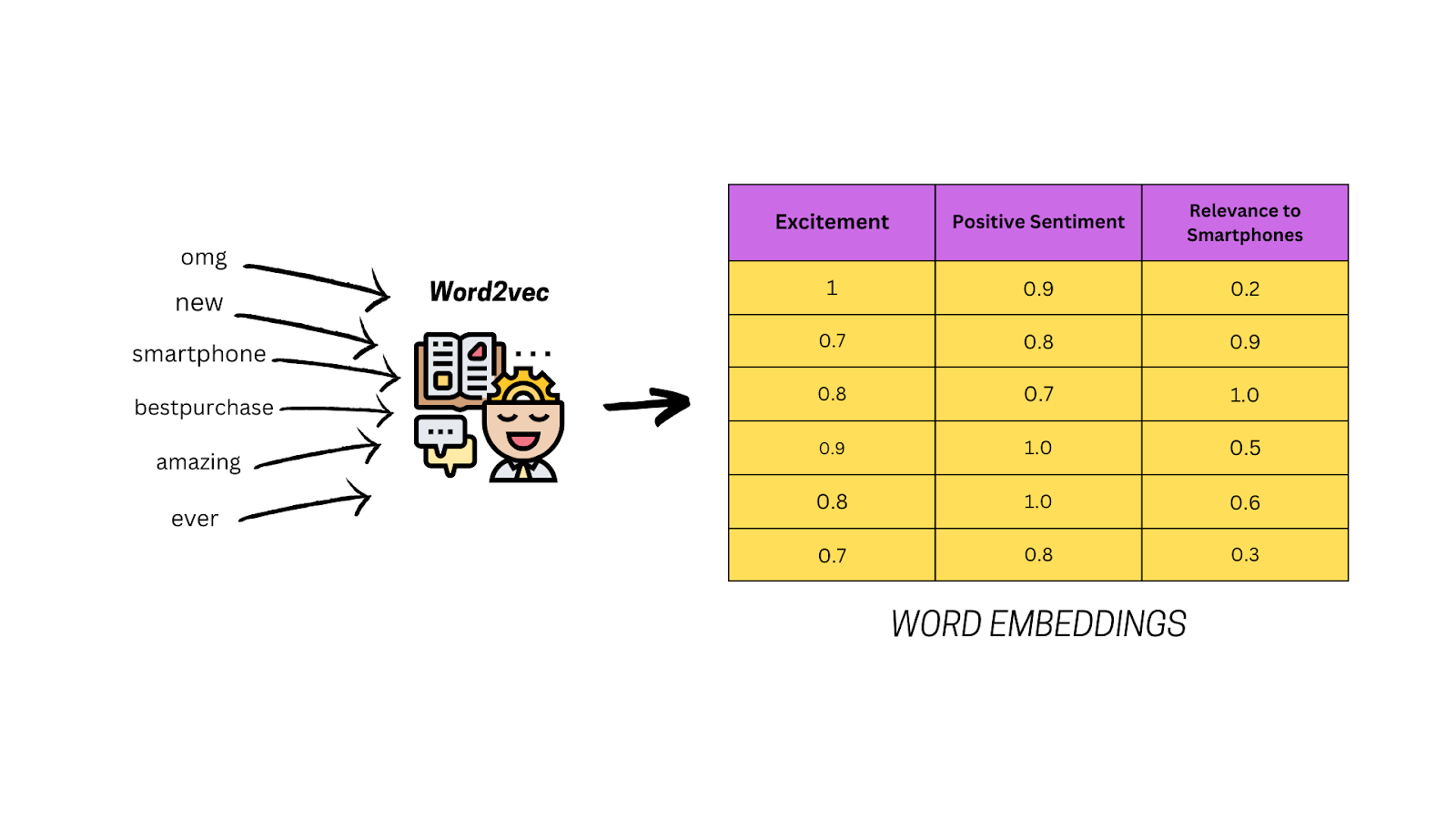
- Word Embeddings: These are more advanced techniques like Word2Vec or GloVe that convert words into dense numerical vectors. These vectors reflect the meanings and connections between words. For instance, “king” and “queen” may have similar vectors due to their relationship.
For more on feature extraction refer our blog on vectorisation.
Text-Analysis
- Part-of-Speech (POS) Tagging: This involves labeling words with their grammatical functions, such as identifying “love” as a verb and “product” as a noun.
- Named Entity Recognition (NER): This process finds specific names of people, companies, or places. For instance, in the sentence “Apple launched a new iPhone,” NER recognizes “Apple” as a business.
- Sentiment Analysis: This technique assesses the emotional tone of text, categorizing it as positive, negative, or neutral. For example, “I love this product!” shows a positive feeling.
- Dependency Parsing: This method examines how words relate to each other in a sentence to understand its structure. For example, it shows that “love” is the action and “product” is what is loved in “I love this product.”
Sentiment Analysis of a Tweet – Example of Stages of NLP
Now, what’s a great concept without a great example? Let us now see an example of Sentiment Analysis of Tweets about a Product Launch! A company has launched a new smartphone and wants to analyze customer feedback on Twitter to determine whether the sentiment is positive, negative, or neutral. Let’s begin!
Step 1: Text Preprocessing
“OMG! 😍 Just got the new SmartPhoneX! It’s AMAZING! #SmartPhoneX #BestPurchase ever! Check it out: “link of product”!
- Tokenization: Split the text into smaller units (tokens):
Tokens:["OMG", "Just", "got", "the", "new", "SmartPhoneX", "It’s", "AMAZING", "BestPurchase", "ever"]. - Lowercasing: Convert all text to lowercase to ensure consistency:
["omg", "just", "got", "the", "new", "smartphonex", "it's", "amazing", "bestpurchase", "ever"].- Stop Word Removal: Remove words like
"just," "the," "it’s,"which don’t add much meaning. - Processed Tokens:
["omg", "got", "new", "smartphonex", "amazing", "bestpurchase", "ever"]. - Text Cleaning: Remove URLs, hashtags, and emojis.
After cleaning :Final Tokens: ["omg", "got", "new", "smartphonex", "amazing", "bestpurchase", "ever"].
Step 2: Feature Extraction
Next, we need to convert the cleaned text into numerical data for analysis. Here are the methods:
- Bag of Words (BoW): In this method, all the words from tweets are shown as a matrix that counts how often each word appears. For instance, if the dataset includes words like [“amazing”, “smartphonex”, “bestpurchase”], the tweet would be shown as: [1, 1, 1] (meaning each word appears once).
- TF-IDF: Words such as “smartphonex” and “amazing” receive a higher score because they are significant and not very common.
- Word Embeddings: With techniques like Word2Vec or GloVe, words like “amazing” and “bestpurchase” are converted into vectors that reflect their meaning and context.
Step 3: Text Analysis
Sentiment Analysis:
- Now, that we have converted natural human language into numbers, we can use classical machine learning algorithms to build a classification model using labelled dataset. And using this model all new tweets can be classified!
- Analysing the sentiment of the tweet using a machine learning model or sentiment library.
- The model detects positive words like
"amazing," "bestpurchase,"and assigns the tweet a positive sentiment score.
Named Entity Recognition (NER):
- Identify key entities in the tweet, such as
"SmartPhoneX"(the product). - This allows us to link the sentiment to the specific product being mentioned.
Topic Modeling (Optional):
- If analyzing multiple tweets, we can detect recurring themes or topics, such as
"battery life,""camera,"or"design."You can read more in Topic modelling here – Click me!
Results
After processing thousands of tweets:
- Positive Tweets: 80%
- Negative Tweets: 15%
- Neutral Tweets: 5%
The company can conclude that the majority of customers are happy with the new smartphone, and key words like "amazing" and "bestpurchase" indicate strong satisfaction.
Conclusion
NLP connects human language with machines, allowing computers to understand, interpret, and create text efficiently. It simplifies text processing into distinct steps: preprocessing, feature extraction, and analysis. This technology supports tools like virtual assistants, sentiment analysis, and translation. As NLP improves, it changes how we communicate and make decisions based on data, creating many new opportunities for innovation.
Do leave a comment about what you think NLP can be used for and how? Share your ideas and projects that you wish to build on NLP!